Intro
Kmeans algorithm 은 군집화 (Clustering) 알고리즘으로 label이 없는 비지도학습(Unsupervised learning) 에 속하는 알고리즘이다. 생각해보면 군집화 라는 말 속에 이미 비지도 학습이라는 걸 알 수 있다. KNN과 헷갈리지말자! KNN 알고리즘은 label이 있어서 어떤 새로운 data가 주어졌을 때 가장 가까운 data를 선택하고 그 data 의 label을 이용한다. 즉 지도학습 (Supervised learning) 이다.
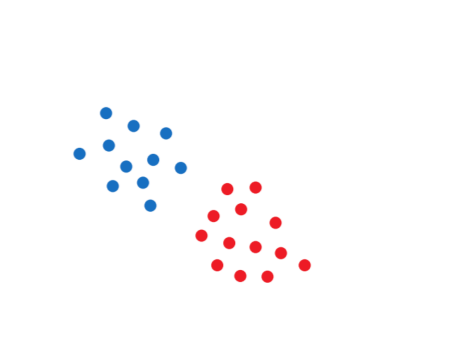
Kmean 구하기
Kmeans 알고리즘은 간단하다. k 개의 center를 정하고 점차 중심으로 조정해나간다. 여기서 data 란 [x_1,x_2,x_3, … , x_n] 의 n차원 배열이라고 생각하자. 알고리즘은 다음과 같다.
Algorithm
- k 개의 random points 선택. 다른 말로 하면 random k 개의 center를 정한다
-
다음 과정 반복
1) Centers to Clusters
: 각 data point들을 가장 가까운 center에 배정한다. 각 data point는 특정한 center 를 가지게 된다.2) Clusters to Center
: 배정된 data point들 기반으로 center를 업데이트 한다. 여기서 새로운 center 는 각 center에 배정된 data의 평균으로 업데이트한다.
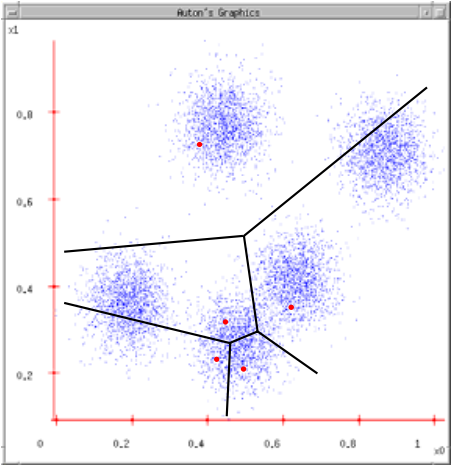
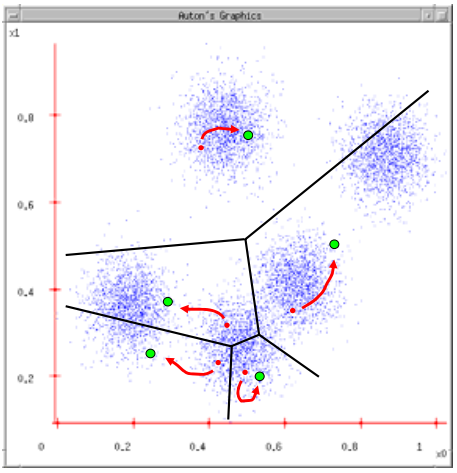
위 그림에서 처음에는 빨간 점의 random한 점으로 군집화가 이루어지고, 각 data point에서 가장 가까운 빨간 점을 찾아 center로 배정한다. 그 다음 각 배정된 data point들의 평균으로 세로운 center 녹색점을 구하고, 이를 반복한다.
Reference
https://www.cs.cmu.edu/~02251/recitations/recitation_soft_clustering.pdf